|
Having looked at each section of 'Stairway to Heaven' in detail, now we can draw conclusions and address why it's one of the greatest achievements in rock history. My answer to why it's so great is its organic development – the way the melody and harmony of the verses grow out of what came before, continuously blending old material with new material. This graph illustrates: 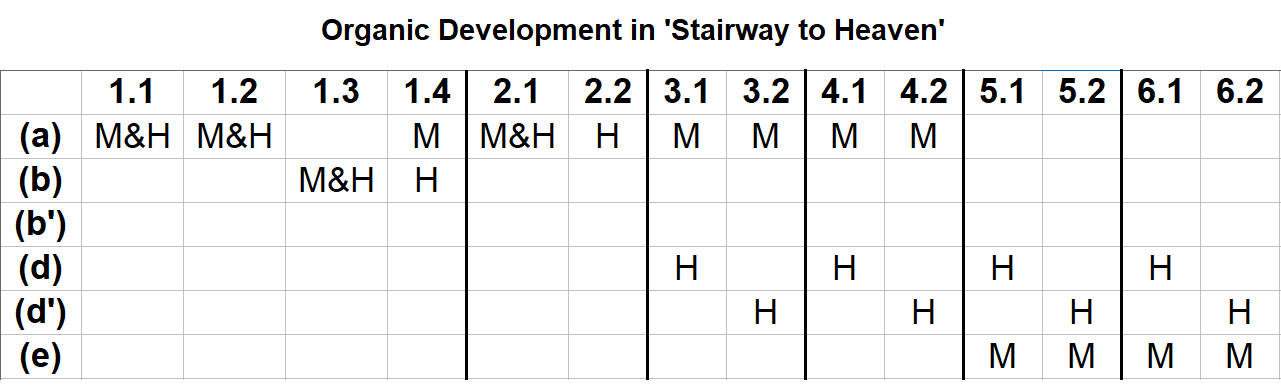 The x axis indicates the verse # and phrase #, separated by a period (ex: 1.4 means verse 1, phrase 4; 3.1 means verse 3, phrase 1). The y axis refers to the phrases. M = melody H = harmony So the melody and harmony are together for the first three phrases of the first verse, and the first phrase of the second verse, but they are split for the fourth phrase of the first verse, and all of the third through sixth verses. It is that split that allows for organic development. Because when the harmony uses the new (d) phrase in verse 3, the melody simultaneously keeps the (a) phrase. Then in verse 5, the melody uses the new (e) phrase, while the harmony simultaneously keeps the (d) harmonies. Each step grows out of what came before by incorporating something new while also retaining something old. The fundamental goal for any composer is to keep the material familiar and internally consistent enough so that it clearly belongs together, but different enough to avoid monotony. A succession of unrelated material will appear disjointed and confusing, while a succession of unchanging material will become predictable and boring. Compositional skill is in large part the ability to balance the two. And one of the best ways to strike that balance is through structure. Indeed, the organic growth and structure of 'Stairway to Heaven' strikes that balance as well as any piece of music I've ever encountered.
0 Comments
One aspect I've ignored so far is tempo. The song gradually builds speed, before winding down again at the end. 0:00-0:54 Introduction: 64 beats in 53.8 seconds = 71.4 beats per minute 0:54-1:48 Verse 1: 64 beats in 53.7 seconds = 71.5 bpm 1:48-2:15 Verse 2: 32 beats in 26.8 seconds = 71.6 bpm 2:15-2:40 Transition A 1: 32 beats in 25.0 seconds = 76.8 bpm 2:40-3:07 Verse 3: 36 beats in 27.6 seconds = 78.3 bpm 3:07-3:31 Transition A 2: 32 beats in 23.4 seconds = 82.1 bpm 3:31-3:57 Verse 4: 36 beats in 26.5 seconds = 81.5 bpm 3:57-4:20 Transition A 3: 32 beats in 23.0 seconds = 83.5 bpm 4:20-4:45 Verse 5: 36 beats in 25.5 seconds = 84.7 bpm 4:45-5:08 Transition A 4: 32 beats in 22.0 seconds = 87.3 bpm 5:08-5:35 Verse 6: 36 beats in 25.3 seconds = 85.4 bpm NOTE: The measure that connects Verse 6 and Transition B 1 uses a fermata to artificially extend its temporal duration, which skews the numbers. To be consistent, I'm omitting that measure from this analysis. 5:35-5:56 Transition B 1: 31.5 beats in 20.1 seconds = 94.0 bpm 5:56-6:45 Solo: 80 beats in 48.8 seconds = 98.4 bpm 6:45-7:47 Verse 7 6:45-7:27 [vocal]: 18 measures = 72 beats in 42.3 seconds = 102.1 bpm 7:27-7:47 [instrumental]: 28 beats in 17.5 seconds = 96.0 bpm NOTE: I'm again omitting the final measure as it uses another fermata, which skews the numbers. 7:47-8:02 Coda: freely (not in rhythm) Here's the same information in the form of a line graph: 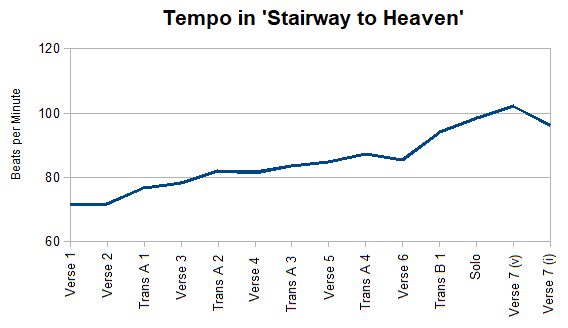 With two minor exceptions that fall within the margin of error, the tempo consistently increases throughout the song until the end. And this was done very much on purpose. "When I did studio work," acknowledged Jimmy Page, "the rule was always: you don't speed up. That was the cardinal sin, to speed up. And I thought, right, we'll do something that speeds up" (Wall, page 242).
Interestingly, the climax of the song as a whole comes at 5:56 (at the onset of the solo), but the tempo's climax is at 6:45 (at the onset of verse 7), where it peaks at 102 beats per minute. SOURCES Wall, Mick. 2008. When Giants Walked the Earth: A Biography of Led Zeppelin. St. Martin's Griffin, New York, NY. While the first five and a half minutes illustrate sophisticated organic growth, the solo is entirely comprised of repetitions of a new two-bar phrase (g). The rhythmically unstable Transition B followed by new material emphasizes the arrival of the solo as the climax of the song. 5:56-6:45 (D) Solo (20 measures) (g) |a G |F | x10 The seventh and final verse adopts the same (g) two-bar phrasing of the solo, repeating it 13 more times (for a total of 26 measures) with Plant adding vocals to the first nine phrases. 6:45-7:47 (D') Verse 7 (26 measures) 6:45 (g) |a G |F | “As we wind...” 6:50 (g) |a G |F | “Our shadows...” 6:54 (g) |a G |F | “There walks...” 6:59 (g) |a G |F | “Who shines...” 7:04 (g) |a G |F | “How everything...” 7:08 (g) |a G |F | “And if you listen...” 7:13 (g) |a G |F | “The tune will come...” 7:18 (g) |a G |F | “When all are...” 7:22 (g) |a G |F | “To be a rock...” 7:27 (g) |a G |F | [instrumental] 7:32 (g) |a G |F | [instrumental] 7:37 (g) |a G |F | [instrumental] 7:42 (g) |a G |F | [instrumental] The final four phrases are instrumental and ritard the tempo, leading to... The coda wraps things up be reprising the title lyrics and melody used several times earlier in the song. This final iteration, however, omits any underlying chord changes, leaving Plant's vocals fully exposed.
7:47-8:02 Coda “And she's buying...” Continuing the organic development we saw in verse 3, verse 5 retains the (d) harmonies while simultaneously introducing the new (e) melody. 4:20-4:45 (C) Verse 5 (9 measures) 4:20 (d & e) |C G |a |C G |a | “If there's a bustle...” 4:31 (d' & e) |C G |a |C G |a |C G | “There are two paths...” Verse 6 is identical to verse 5, just with different lyrics.
5:08-5:35 (C) Verse 6 (9 measures) 5:08 (d & e) |C G |a |C G |a | “Your head...” 5:19 (d' & e) |C G |a |C G |a |C G | “Dear lady...” Verse 3, like verse 2, contains two phrases. Those phrases are identical except that the latter is extended by a single measure (five bars long instead of four). Both reprise the (a) melody from the first and second verses, but with new (d) harmonies. 2:40-3:31 (B) Verse 3 (9 measures) 2:40 (a & d) |C G |a |C G |a | “There's a feeling...” 2:52 (a & d') |C G |a |C G |a |C G | “In my thoughts...” This third verse cannot be called a new section because it brings back an old melody. But it also cannot be called an old section, either, because the chords are new. So it's half new, half old. This is a technique known as organic development because the music grows out of what came before, just like a seed sprouts and flowers. I analyzed the organic development of 'Good Times Bad Times' earlier. This is the same technique, but on a much grander scale. While Verse 3 is the first time those (d) harmonies are used, they will be heard again six more times (two each in verses 4, 5, and 6): 3:31 (d) Verse 4 3:42 (d') Verse 4 4:20 (d) Verse 5 4:31 (d') Verse 5 5:08 (d) Verse 6 5:19 (d') Verse 6 Verse 4 is identical to verse 3, just with different lyrics.
3:31-3:55 (B) Verse 4 (9 measures) 3:31 (a & d) |C G |a |C G |a | “And it's whispered...” 3:42 (a & d') |C G |a |C G |a |C G | “And a new day...” There are two different transitions in 'Stairway to Heaven'. The first, which I call "Transition A", is heard a total of four times. The second, "Transition B", is heard only once. I've blogged about both transitions before - Transition A was part of my rhythmic displacement series, and I compared the rhythmic instability of Transition B to The Beatles' 'Here Comes The Sun' in another post. All four Transition As consist of four phrases, each comprised of identical two-measure harmony (a-D). What's different about the total 16 phrases (four Transition As x 4 phrases each = 16 total phrases) are Robert Plant's vocals. Five of those 16 phrases include the line "makes me wonder" while the remaining nine are instrumental. (NOTE: There are two phrases where he sings "Oh", but I'm counting those as instrumental.)  2:15-2:40 Transition A 1 (8 measures) 2:15 (c) |a |D | “Makes me wonder...” (beat 4) 2:21 (c) |a |D | [instrumental] 2:27 (c) |a |D | "Makes me wonder..." (beat 2) 2:34 (c) |a |D | [instrumental]  3:07-3:31 Transition A 2 (8 measures) 3:07 (c) |a |D | “Makes me wonder...” (beat 2) 3:13 (c) |a |D | [instrumental] 3:19 (c) |a |D | "Makes me wonder..." (beat 2) 3:25 (c) |a |D | [instrumental]  3:55-4:20 Transition A 3 (8 measures) 3:55 (c) |a |D | [instrumental] 4:03 (c) |a |D | [instrumental] 4:09 (c) |a |D | [instrumental] 4:14 (c) |a |D | [instrumental]  4:45-5:08 Transition A 4 (8 measures) 4:45 (c) |a |D | "Makes me wonder..." (beat 4) 4:51 (c) |a |D | [instrumental] 4:57 (c) |a |D | [instrumental] 5:02 (c) |a |D | [instrumental] The final transition, the only iteration of Transition B, is quite different from Transition A, and particularly interesting.
5:35-5:56 Transition B 1 (8 measures) 5:35 (f) |Dsus4 |D |C | | [instrumental] 5:46 (f') |Dsus4 |D |C |G/B | [instrumental] But I've already considered this Transition B in a previous blog, so there's no need to repeat it here. I've already written about the first verse of 'Stairway to Heaven' in my series on rhythmic displacement, so I'll consider it only briefly here. The first verse is structurally identical to the instrumental introduction. Both employ four phrases, each four measures long, the first two of which are identical, the last two of which are comparable and so labeled (b) and (b'). Most interesting is that Plant's second verse ("There's a sign...") begins early, at 1:34, overlapping with the fourth and final phrase of the first verse. 0:54-1:48 (A) Verse 1 (16 measures) 0:54 (a) |a E/g# |C/g D/f# | FM7 |a | “There's a lady...” 1:07 (a) |a E/g# |C/g D/f# | FM7 |a | “When she gets...” 1:21 (b) |C D |FM7 a |C G |D | “Ooo...” 1:34 (a & b') |C D |FM7 a |C D |FM7 | “There's a sign...” Part of me wants to label the third and fourth phrases as their own distinct section. I could see this as a bridge instead of part of the verse. But bridges are defined by contrast to the verses, and while there certainly is some contrast, there is also a lot of similarity. The first four chords of the phrase in question (C-D-FM7-a) are the same as the last four chords of the previous phrases. The harmonic rhythm is faster (covering two measures instead of three), and the chords are all in root position (no inversions this time), but there is a clear and strong harmonic similarity. Now, there are many songs where the verses and bridges share strong harmonic similarities but there are other differences, such as melody, that distinguish the two sections. But in 'Stairway', there is also a clear and strong melodic similarity. While the first half of the phrase in question is different (“Ooo...”, shown below with blue notes), the second half employs the same pattern as the previous phrases. They even use the same lyrics (“and she's buying a stairway to heaven”, shown in red).  Finally, the lyrics suggest that these (b) phrases are not a bridge because they include the title (which was also heard earlier in the first phrase of verse 1). While it's not unheard of for the title to be lifted from the bridge (check out 'She's A Woman', 'Rain', or 'For No One' by The Beatles), it is rather rare. It's much more common for the title to be lifted from verse lyrics than from bridge lyrics. So all of this compels me not to label it as a bridge, but as part of the verse. The contrast that is there isn't strong enough to justify an independent formal level label Verse 2 is half as long as verse 1, and it's identical to the first half of verse 1 (save for the lyrics).
1:48-2:15 (A') Verse 2 (8 measures) 1:48 (a) |a E/g# |C/g D/f# | FM7 |a | “In the tree...” 2:01 (a) |a E/g# |C/g D/f# | FM7 |a | [instrumental] The reason for this abbreviation is because we've heard the (a)(a)(b)(b') pattern twice already (once from 0:00-0:54 as the intro, then again from 0:54-1:48 as the first verse). To avoid any threat of monotony, this third iteration (and every subsequent iteration) is curtailed to two phrases. This truncated second verse leads to the first transition, which I'll consider tomorrow. Having completed the overview, we now turn to the individual sections for a more detailed look.
At their most fundamental, introductions set up what comes next. This almost always means the music heard in the intro will be heard again later in the song. And 'Stairway to Heaven' is no exception. The instrumental introduction of 'Stairway' consists of four phrases, the first two of which are essentially identical and the second two of which are comparable. 0:00-0:54 (A) Introduction (16 measures) 0:00 (a) |a E/g# |C/g D/f# | FM7 |a | [instrumental] 0:14 (a) |a E/g# |C/g D/f# | FM7 |a | [instrumental] 0:27 (b) |C D |FM7 a |C G |D | [instrumental] 0:40 (b') |C D |FM7 a |C D |FM7 | [instrumental] The (a) phrases are heard a total of six times: twice each in the introduction, first verse, and second verse. 0:00 (a) Intro [instrumental] 0:14 (a) Intro [instrumental] 0:54 (a) Verse 1 “There's a lady...” 1:07 (a) Verse 1 “When she gets there...” 1:48 (a) Verse 2 “In the tree...” 2:01 (a) Verse 2 [instrumental] The (b) and (b') phrases are heard a total of four times: twice each in the intro and first verse. 0:27 (b) Intro [instrumental] 0:40 (b') Intro [instrumental] 1:21 (b) Verse 1 “Ooo...” 1:34 (b') Verse 1 “There's a sign...” It's worth noting how both the (a) and (b) phrase are only used in pairs – they never once appear as a single phrase. It's also worth noting how the (a) and (b) phrases are used together in the intro and first verse, but the second verse uses only the (a) phrases. We'll address why that is in a subsequent blog. Earlier, I blogged about organic development in 'Good Times Bad Times'. It's an extremely sophisticated song, at least from a structural standpoint. There's no way they could top that, right? WRONG – They were just getting started! If you thought the organic development and structure of 'Good Times Bad Times' was sophisticated, then the expanded and elaborated use of both in 'Stairway to Heaven' will blow your mind. Now, many people before me have analyzed 'Stairway', and the vast majority of them strike me as deeply problematic. Most analyses oversimplify by differentiating sections that are clearly and strongly related. This robs the music of its organic development. Others try to over-complexify (I'm might be making up that word), as if their spectacularly arcane analysis will somehow make the music better. Yes, this is an extremely sophisticated (and to my knowledge unique) design for a song, and so it absolutely requires analysis that does justice to its nuances. But I have major problems when analyses are more complicated than the subject being analyzed. The point of analysis is to better understand that which is being analyzed. And if the analysis is more thorny than the subject, then that analysis only inhibits rather than facilitates understanding. The trick, then, is balance – don't make the analysis so simple that it misses the musical sophistication, but don't make it unnecessarily complicated, either. With that caveat in mind, here's my take on 'Stairway to Heaven'. 0:00-0:54 (A) Introduction (16 measures) 0:00 (a) |a E/g# |C/g D/f# | FM7 |a | [instrumental] 0:14 (a) |a E/g# |C/g D/f# | FM7 |a | [instrumental] 0:27 (b) |C D |FM7 a |C G |D | [instrumental] 0:40 (b') |C D |FM7 a |C D |FM7 | [instrumental] 0:54-1:48 (A) Verse 1 (16 measures) 0:54 (a) |a E/g# |C/g D/f# | FM7 |a | “There's a lady...” 1:07 (a) |a E/g# |C/g D/f# | FM7 |a | “When she gets...” 1:21 (b) |C D |FM7 a |C G |D | “Ooo...” 1:34 (a & b') |C D |FM7 a |C D |FM7 | “There's a sign...” 1:48-2:40 (A') Verse 2 (8 measures) 1:48 (a) |a E/g# |C/g D/f# | FM7 |a | “In the tree...” 2:01 (a) |a E/g# |C/g D/f# | FM7 |a | [instrumental] 2:15-2:40 Transition A 1 (8 measures) 2:15 (c) |a |D | “Makes me wonder...” 2:21 (c) |a |D | [instrumental] 2:27 (c) |a |D | "Makes me wonder..." 2:34 (c) |a |D | [instrumental] 2:40-3:31 (B) Verse 3 (17 measures) 2:40 (a & d) |C G |a |C G |a | “There's a feeling...” 2:52 (a & d') |C G |a |C G |a |C G | “In my thoughts...” 3:07-3:31 Transition A 2 (8 measures) 3:07 (c) |a |D | “Makes me wonder...” 3:13 (c) |a |D | [instrumental] 3:19 (c) |a |D | "Makes me wonder..." 3:25 (c) |a |D | [instrumental] 3:31-3:55 (B) Verse 4 (9 measures) 3:31 (a & d) |C G |a |C G |a | “And it's whispered...” 3:42 (a & d') |C G |a |C G |a |C G | “And a new day...” 3:55-4:20 Transition A 3 (8 measures) 3:55 (c) |a |D | [instrumental] 4:03 (c) |a |D | [instrumental] 4:09 (c) |a |D | [instrumental] 4:14 (c) |a |D | [instrumental] 4:20-4:45 (C) Verse 5 (9 measures) 4:20 (d & e) |C G |a |C G |a | “If there's a bustle...” 4:31 (d & e') |C G |a |C G |a |C G | “Yes, there are two paths...” 4:45-5:08 Transition A 4 (8 measures) 4:45 (c) |a |D | [instrumental] 4:51 (c) |a |D | "Makes me wonder..." 4:57 (c) |a |D | [instrumental] 5:02 (c) |a |D | "Makes me wonder..." 5:08-5:35 (C) Verse 6 (9 measures) 5:08 (d & e) |C G |a |C G |a | “Your head..” 5:19 (d & e') |C G |a |C G |a |C G | “Dear lady...” 5:35-5:56 Transition B 1 (8 measures) 5:35 (f) |Dsus4 | D |C | | [instrumental] 5:46 (f') |Dsus4 | D |C |G/b | [instrumental] 5:56-6:45 (D) Solo (20 measures) (g) |a G |F | x10 6:45-7:47 (D) Verse 7 (18 measures) 6:45 (g) |a G |F | “As we wind...” 6:50 (g) |a G |F | “Our shadows...” 6:54 (g) |a G |F | “There walks...” 6:59 (g) |a G |F | “Who shines...” 7:04 (g) |a G |F | “How everything...” 7:08 (g) |a G |F | “And if you listen...” 7:13 (g) |a G |F | “The tune will come...” 7:18 (g) |a G |F | “When all are...” 7:22 (g) |a G |F | “To be a rock...” 7:47-8:02 Coda “And she's buying...” With the overview complete, it's time for a detailed look at each of the individual component parts that comprise the song. I plan to dedicate one blog to each section over the next week or two.
We've already seen how 'Dazed and Confused' and 'Houses of the Holy' displace one beat (though in opposite directions), how 'When the Levee Breaks' displaces one measure, and how 'Stairway to Heaven' displaces by two beats and by an entire phrase. Next and last in this series is a song that displaces half a beat: 'Black Dog', the initial track of Led Zeppelin IV (1971). In this case, a seven-note pattern lasting nine eighth notes...  ...is repeated over common time measures, yielding rhythmic displacement of a single eighth note (half a beat) per iteration.  Lesser musicians might have repeated these musical ideas more or less the same each time. But Zeppelin, ever attentive to detail, found ways to subtly alter their music in a way simultaneously familiar yet different through rhythmic displacement. And that, I suspect, is one trait (of many) that separates the good bands from the great bands.
|
Aaron Krerowicz, pop music scholarAn informal but highly analytic study of popular music. Archives
August 2019
Categories
All
|
 RSS Feed
RSS Feed
